一个好的idea是怎么提出来的?为什么你研究了好几年却什么也没提出来?
在一篇文章中,我讲了如何判断一个idea的档次。现在我想讲的是,怎么提出一个idea。当然了,我所说的idea最好符合我之前文章里面讲的标准:
我们应该怎么提出一个idea呢?对于这个问题,我先讲一种思路吧。一种95%的导师都会告诉大家的思路,那就是:多读论文,看看别人的论文里面有什么毛病,然后你去把这个毛病给解决了,你就有了论文了。
这是标准的错误答案!这是标准的错误答案!这是标准的错误答案!
扪心自问,大家有多少人都是按照这个思路去做研究的?有多少人真的根据这个思路发表了论文?又有多少人按照这种思路能发表真正有价值的顶尖的论文?
据我所知,按照这种思路做研究的学生占90%以上。可悲!可怜!可恨!恨的是这些没有责任心的导师和网上答虚假信息。诺大的知乎,居然没有人来告诉大家这么做不对。居然很多人还倡导这种思路。在介绍真正的思路之前,我先给大家分析一下为什么这种思路的错误的。
我一直在强调逻辑。那我就从最最最最最基本的逻辑来给大家证明一下这种思路的错误。首先,你去读一篇论文。你是读者。你再怎么聪明,你对于一篇论文的理解,肯定不如作者理解的深。何况正如我之前写的文章里面讲的一样,如果你的逻辑思维能力不够强大,很大的概率你会被自己错误的思路给误导。那么你的理解就浅薄了。那么在这种情况下,你认为你找到的毛病,作者会不知道么?你能发现一篇论文里面存在的问题,那么作者肯定也明白这个问题。那么为什么作者不去把这个问题解决了呢?为什么作者要把这个机会留给你呢?你难道认为你比作者聪明,比作者对他的论文理解还深入么?
当然了,肯定有人会说,我要是作者的话,我会留一手,等下一篇论文再解决这个问题。我可以负责的告诉你,没有作者会这么想。作者都是会把所有的子弹打光,把能做的都做好,这样才能保证文章录用。你要是作者,你在投论文的时候内心肯定是担心论文会被拒稿。作者不会自信到把贡献分摊到下一篇论文,然后给这一篇论文的投稿带来更大的不确定性。这是不太可能发生的。当然了也有例外,我以后会给大家讲。但是总的来说,这种情况不存在。
那么如果你按照这种思路走下去,你找到了一个毛病。你开始研究解决这个毛病。现在我说一个情况,你看看你有没有发生过?你开始着手解决别人论文里的毛病,然后你发现没有思路,然后你再去看论文,再去找相关的资料,然后再去做实验。反复折腾了一年,最后还是没解决。或者是,你发现这个毛病非常迅速的就被你解决了。两个礼拜以后你成功地解决了这个问题,你非常开心。这两种情况,无论是哪一种,你都发表不了论文。因为第一种情况说明,你这个问题非常可能它压根就解决不了。人家作者没去解决这个问题正是因为这个问题是非常难以解决的,除非有爱因斯坦级别的人物才有可能解决。第二种情况说明,这个问题作者之所以没去解决,是因为这个问题太小了。就算解决了也没啥贡献。这两种情况无论是哪一种,都将是你按照挑别人论文毛病的思路去做科研所带来的恶果!
现在我来告诉大家一种思路,看完这种思路以后,大家自行判断我说的思路对不对。
首先我们得明白,一篇论文里面其实很多部分都有误导性,甚至是错误。尤其是档次比较差的论文。当然了,有些所谓的档次高的论文,比如饱受大家诟病的infocom,虽然是CCF A类会议,里面的论文很大一部分都有误导性。这种论文的实验都很难复现,就更不用说什么创新了。所以挑出来这些文章的毛病,其实是一件很容易的事情。但是这些毛病也会把你误导的。既然现实中,大量论文里面都有着问题,那么我们读文章的时候到底能从文章里面学到什么?
知乎:为什么你提出的idea会和别人重合?怎么写introduction和abstract?
我在这个文章里面给大家讲了一个idea应该传达的8条信息。这8条信息中,最关键的其实是一个idea的insight,或者叫intuition。也就是第6条信息:你发现了什么新的现象或者信息,并利用这一现象提出一个新的方法来避免前人的问题。
我可以从审稿人的角度,负责任的告诉大家,一篇论文哪怕里面的算法设计的一塌糊涂,只要论文里面的insight能够给大家带来新的启发,带来新的知识,带来新的理解,那么这一篇论文就一定会让审稿人眼前一亮。这时候,哪怕实验效果再假,论文只要写得清清楚楚,大概率也是会被录用的。所以,insight才是一个文章的核心!一篇文章哪怕到处都是错误,但是文章的insight很大概率是不会错的!而且一篇论文,哪怕是infocom的论文,里面的insight也都会描述的比较清晰,比较直观。因此,我们在读论文的时候,核心是要理解这个论文的insight。
掌握了一个论文的insight,就相当于掌握了一件武器。当你读了你的方向上的5篇很有代表性的论文以后,你应该深入理解并且掌握了5个insight。这时候摆在你面前的就是5个不同的武器。那你现在需要做的就是,再深入思考思考这些insight之间的关联。然后你要想一想,这些insight背后的深层次的含义是什么?是什么导致了这些现象?能不能从中发现一些更加有规律性的现象?这时候,你就离提出一个有价值的idea不远了。
我想一个合适的例子。这种例子太多了。我来讲一讲svm和由它产生的新的科研方向吧。
SVM就是支持向量机。这个方法用于给线性不可分的数据进行分类。有的同学可能不知道什么叫线性可分,什么叫线性不可分。我去找个图。我找到了一个知乎上面的文章,讲解SVM的,接下来我会用到他这篇文章里面的图来给大家简略地介绍一下SVM的insight是什么:https://zhuanlan.zhihu.com/p/77750026
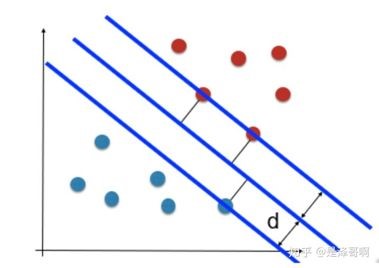
在这张图里面,蓝色的点和红色的点代表两种类别的数据。横纵坐标分别表示这个数据的两个特征。比如我们用蓝色表示没有买房子的人,我们用红色表示已经买了房子的人。我们用这个人的收入和当地的房价成当作特征。例如(15,3)表示这个样本的收入是15万一年,当地房价是3万以平米。那么现在我们拿到了这些数据以后,我们要根据一个人的收入和当地的房价还推算一这个人到底买了房子没有。当我们得到了一些收入,房价,还有是否买房的数据以后,我们可以把这个数据画在二维的平面上,于是就有了上面那张图。那么现在问题是,如果有一个人他的收入是20,房价是5,那么他买了房子没有呢?我们可以从上面那张图看出来,两类人群明显处于蓝色直线的两侧。也就是说,是否买房可以通过我们画一条直线来判断。这条直线就叫做分界面,整个模型就是一个线性分类器。可以被一条直线分类的数据就是线性可分的。那么线性不可分就是另一种情况了:
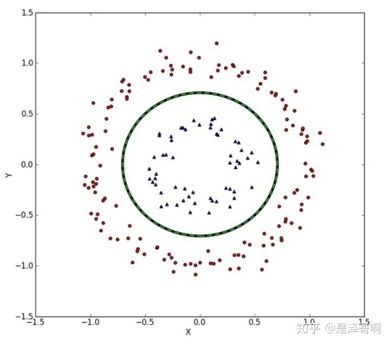
还是上面那个例子,如果我们把数据画出来长成这个样子,想要区分两个类别,我们就需要画一个圆。圆的里面是一类,圆的外边是另外一类。这种情况下,如果你用一条直线去分割两类数据,你会发现不管你怎么画这条直线,总是会把一些数据错误划分。因此不存在一条直线将两类数据完美分开。于是这种数据叫做线性不可分。SVM就是为了给这种线性不可分的数据做分类的。当然了,大家可能会疑问,为什么不能直接设计一个非线性的分类器呢?这主要是因为非线性包括所有除了线性以外的函数,我们不知道用那种函数来形式化。
那么SVM凭什么可以分类呢?它的insight是什么呢?SVM说,我认为啊,这些数据之所以线性不可分,是因为我们观察这些数据的维度太少了。你别看这些数据在二维平面上是线性不可分的,但是如果我们把两类数据增加一个特征,也就是一个维度,就可以用线性分类器进行分类啦。比如我们将刚才那张图的数据,增加一个维度,达到下面这张图的效果:
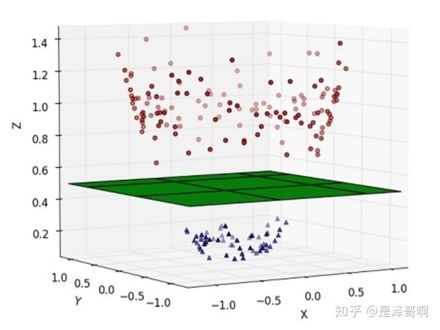
这相当于,我把之前二维平面上的数据,变成了三维空间上的数据。原本是二维的数据,现在在空间是有了一个高度。我们把两类数据放在不同的高度,那么只需要在中间切一刀,也就是用一个平面就可以将两类数据分开了。而平面也属于线性分类器。
于是乎,这就成为了SVM的第一个insight:线性不可分的数据,我们可以把他们映射到一个高维空间上,让他们在高维空间做到线性可分。当然了,SVM还有两个insights,在这里我就不过多展开了。我想说的是,根据这个insight后面诞生了一个新的科研方向,在这方向上诞生了非常多的idea。而这些idea是怎么样提出来的呢?
我们可以深入思考一下SVM的insight。我们可以想象一下,一个低维空间的数据,被我们用一些方法转换成了高维空间的数据。这种转换不一定非得是SVM才可以完成,你看现在的深度学习,神经网络,都属于是把一个输入的数据,映射到了高维的空间中。只不过是我们可以把这些神经网络的节点来看作成高维度的空间。那么我们现在跳出了SVM的局限,我们可以想象,凡是把低维度数据转换到高维空间,我们都可以有类似的insight。这种低维到高维的转换,有没有缺点呢 ?我们可以想象一下,原本就是二维的信息,现在我们凭空变出第三个维度,如果这个维度设计的不太好,那么会不会使得这种转换对于噪声和微小扰动的容忍度变得很低?比如说刚才的例子中,如果红色的点被放在高度是0.1的平面上,蓝色的点还在高度是0的平面上:
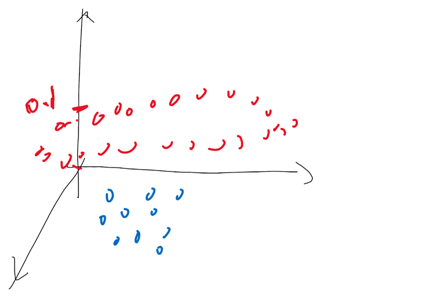
那么只要有超过0.1的误差就会使得样本被错误的分类了。那么现在可以把这个insight再往前推进一步,我们可以想象出下面这种情况:我们故意在低维数据上面增加一些噪声,这样的数据经过转换以后,在高维空间上表现得跟没有加入噪声之前非常不一样,以至于被错误的分类了。在论文“DeepFool: a simple and accurate method to fool deep neural networks”里面,作者就是用这种insight:

在鲸鱼的图片上插入人眼很难识别的微小扰动,以至于这些高纬度的分类器会将鲸鱼错误分类成乌龟。
这就是一个非常好的提出idea的例子。根据低维空间转换高维空间的insight,我们可以在低维数据上加一些噪声,但是人眼对于微小噪声是看不出来的,因此可以在人类无法分辨的前提下,迷惑深度学习网络。利用这个insight到声音里面,我们也可以得到类似的insight:人类对于声音中的微小扰动也无法识别,但是深度学习网络会将这个错误判断。于是就有人提出出了一个攻击语言识别的idea。等等。
在这里我想说的是,我们要提出idea的思路应该是什么样子的呢?我们不应该从挑别人论文的毛病开始,而是恰巧相反,我们应该从理解别人论文的优点开始!我们将别人论文中的优点,主要是insight,深入理解以后,在你自己的领域和研究的背景下面加以扩展,我们就可以得到一些新的现象,进而提出新的idea!
在这里,我劝戒大家,一定要重新审视你自己做研究的思路。很多同学已经沿着挑别人毛病的错误思路上走了好几年了,最终什么也没提出来,什么也没做出来。是时候该改变自己的思路了!我知道,很多同学即使看了我写的文章,即使理解和认同我的观点,但是他们依然不会改变,不会行动。因为他们幻想着,如果我继续按照我的思路,没准我离提出idea就差一点点了,没准再坚持两礼拜我就有突破了。唉,放弃幻想吧!我已经给大家分析过了,这种思路能提出合格的idea的可能性非常低!
现在大家只要转换思路,从挑别人毛病,变成欣赏别人的优点,那么大家就会发现周围可用的工具和资源一下变多了。以前天天挑别人的毛病,你会感觉做实验的时候总是失败,因为你挑的毛病很可能解决不了。现在大家只要实在追寻着正确的insight往前走,而不是在找别人的错误。沿着正确的insight往前努力,你一定可以找到新的insight,这时候你做的实验肯定效果会很明显。因为这种逻辑是正确的,所以你一定可以提出一个漂漂亮亮的idea。
另外,有的同学建议我找一些论文给大家讲一讲里面的逻辑是什么样的。拿一些发表的论文来当作例子给大家分析一下写作的逻辑和技巧。我想的是,要是我自己挑论文就太有倾向性了。我感觉大家如果有兴趣的话,可以把你认为在你的方向上写得很好的论文在下面留言。我会找几个合适的给大家分析分析的。我是学计算机的,计算机相关的论文,只要别太偏,应该都可以。谢谢大家的支持!谢谢大家的支持!
—————————————————-END———————————————————–
我们建立了一个微信公众号:“分享科研经验的科学家”。我们会同步分享科研经验到这个公众号。在微信里,我们的文章可以更加自由地排版。文章也会更加适合阅读和传播。我们相信,经过大家的不懈努力,一定会帮助到越来越多的同学们。请大家关注我们的公众号,并且把这个传播给因为科研而痛苦的同学们。除了扫描二维码,大家还可以通过在微信上搜索“分享科研经验的科学家”来添加我们的公众号 :
