通过一篇顶级会议的论文,给大家讲解一下一篇论文的insight和idea
我现在拿一篇顶级会议的论文当作例子,来给大家剖析一下这篇论文里面的insight和idea。并且帮助大家分析一下,如果从挑别人论文毛病的思路去思考的话,会对这篇论文产生什么样的影响?在下一篇文章中,我还是会拿这个论文当作例子给大家讲解一下,一篇论文里面具体的设计部分应该怎么写。我还会介绍一下不同写作思路对于论文档次高低的影响。
我要介绍的这篇论文的题目是“AirCloud: A Cloud-based Air-Quality Monitoring System for Everyone”。发表在2014年的SenSys会议上。SenSys是CSRanking里面mobile computing领域的三大顶会之一:http://csrankings.org/#/index?mobile&us
这篇论文的链接在这里:https://doi.org/10.1145/2668332.2668346
我之所以选择这篇论文是有两个原因:1,这篇论文的主题是PM2.5的监测。这个主题适用于很多不同的专业。这篇论文本身是计算机的方向的,但是在发表以后,这篇篇论文被环境工程专业,卫星遥感,甚至管理学的论文都引用了。因此我认为这篇论文应该可以被大多数专业的同学们看懂。2,这篇论文的贡献十分巨大!毫不夸张地说,这篇论文开创了一个新的领域:利用廉价的低精度的灰尘传感器,来推算出任意位置的PM2.5浓度,从而使人们可以获取任意位置的精准的PM2.5数值(即使身边没有PM2.5的监测设备)。3,这篇论文的写作很好。因为写得很流畅,我建议大家可以去读一读这篇论文,体会一下作者的逻辑。
我现在给大家介绍一下这篇论文到底做了些什么,也顺便带着大家回顾一下我之前给大家讲的introduction应该怎么写,还有一个idea里面应该包含那些信息。如果之前没看过的同学们,可以去这里看:
为什么你提出的idea会和别人重合?怎么写introduction和abstract? 知乎:为什么你提出的idea会和别人重合?怎么写introduction和abstract?
下面我开始给大家讲一下论文的内容。人们的生活离不开空气。空气质量的好坏关乎人们的健康。近年来由PM2.5引起的问题越来越严重。为了避免PM2.5引起的疾病,人们会选择戴口罩出行,或者干脆呆在家中。不论选择那种方式,人们都需要知道周围PM2.5的情况以后再做出自己的判断。
为了更好地监测空气中的PM2.5,人们会在手机上安装一些空气质量检测的APP。然而,这些APP只能告诉大家一个城市大致的PM2.5指数,或者一个区的PM2.5指数。可惜,这些APP并不能告诉具体到每一个人周围的PM2.5浓度。比如我的手机app告诉我今天北京市的PM2.5指数是50。如果我点进去,还会告诉我海淀区的指数是60。可是如果我想知道我现在所处的大楼附近的PM2.5浓度,这个APP就没法告诉我了。其实,我们只需要关心自己周围,自己能够呼吸到的PM2.5到底有多少就够用了。我们并不需要关心一个城市整体的PM2.5浓度高低。
那么为了监测自己周围的PM2.5浓度,人们需要买PM2.5监测仪。现在市面上有两种PM2.5检测仪。一种是microbalance PM2.5监测仪。这种设备的精度非常高,但是价格在5万到10万美元一台。另一种是基于光散射的监测仪。这种设备精度也不错,可是仍然需要300到1万美元左右,价格依然不便宜。
我们发现,近些年市面上出现了一种不是很贵的的灰尘传感器。PM2.5其实也就是一种细小的灰尘而已。有了便宜的灰尘传感器,是不是就可以制造出一个价格很低的PM2.5监测仪呢?
很遗憾,答案是不。这种灰尘传感器的误差是很大的。直接拿这种传感器的读数当作PM2.5的数值是不行的。如果我们想用这种精度低但是便宜的传感器来检测PM2.5, 那么我们最需要做的就是给这些低精度的传感器进行校正!
———–上面是introduction(跟我之前介绍的idea应该包含的信息完全吻合[1],下面就是具体的设计部分了————–
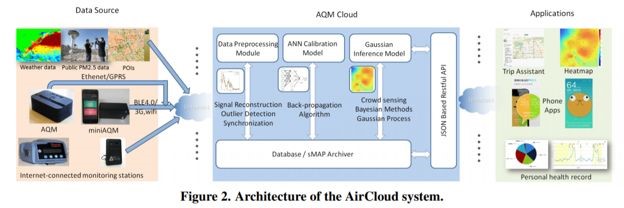
想要校正一个低精度的传感器,最直观的想法就是:我把这个低精度传感器放在一个高精度的PM2.5检测仪旁边。如果传感器的读书是100,PM2.5检测仪度数是150,那么我们就把这个传感器的度数加50就完成校准了。当然了,实际上传感器的校准比这个要复杂一些,因为传感器是测量灰尘的,而灰尘受到空气湿度等气象因素影响很大(这是一个insight)。因此,在论文的6.2章中,作者用了一个神经网络(ANN)来帮助我们完成校准。具体的思路是这样的:我们把一个高精度的PM2.5检测仪和我们低精度的传感器放在同一个地点。我们把传感器的读数和这个位置的温度湿度信息当作输入,把高精度的PM2.5检测仪的数值当作输出来训练一个神经网络。等训练完成以后,我们把这个传感器部署在一个地点以后,我们读取低精度传感器的度数,同时我们也拿到这个地点的温度湿度数据(从天气预报网站获得),我们便可以从训练好的神经网络中获得这个地点真正的PM2.5的数值啦。
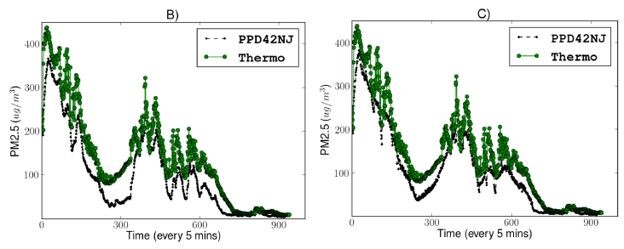
这种校准的方法效果可以在上图中看出来。图B中的黑色线代表着低精度的传感器(PPD42NJ)的读数,绿色线代表着高精度的PM2.5检测仪的度数。图C表示经过神经网络校准以后的传感器读数。很明显,校准以后传感器的读数离真实值已经比校准前接近了。
刚才这个校准的方法要求我们把需要校准的传感器和高精度的PM2.5监测仪放在一起。在实际的使用过程中,人们会携带着传感器去到任何地方。这时候我们不能保证这些传感器周围有一个精准的PM2.5监测仪来帮助它校正。这时候传感器会在长期使用的时候读数产生偏差,如果不及时加以校正,那么多读取的数值将没有意义。

为了解决这个问题,作者做了两件事:(1),在所以低精度传感器出厂之前,把他们所有的数值都调整成一样。这样可以保证每个传感器的读数在任何情况下都是一致的。廉价传感器被放置在上图中的实验舱中,然后利用4.4章中的方法,所有的传感器读数都被调整完毕。(2),AirCloud系统专门将几台低精度的传感器部署在高精度的监测仪周围。由于所有传感器的读数都被调整成一致的了,当一个传感器周围没有高精度监测仪的时候,我们可以利用那些在高精度监测仪周围的传感器来学习读数的变化。并用这个学习到的变化规律来校正其他没有在高精度监测仪周围的传感器。当然了,AirCloud也利用政府已经部署的PM2.5监测站,并且在这些检测站附近也部署了一些廉价传感器,用于校正。政府已经部署的PM2.5监测站所产生的数据都是非常精确的,而且是实时更新的公开的。因此传感器校正后的结果是十分精准的。
当我们把低精度传感器都校正了以后,我们可以把这些传感器都看作是高精度的廉价传感器了。这就解决了论文开始的时候纠结的问题。相比于政府在城市里部署的PM2.5监测站,AirCloud所使用的传感器价格十分低廉同时其精度在经过校正后也很高。因此,作者在城市中大量部署廉价传感器,用于监测政府部署的监测站无法覆盖的街道:
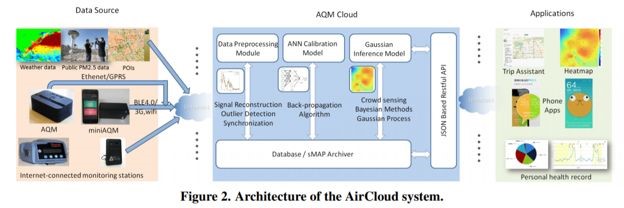
这种大量部署传感器的做法,产生了大量的PM2.5监测的数据。这时,我们产生了一个疑问,我们是否可以利用这些监测的数据来推算出任意位置的PM2.5的真是数值? 也就是说,我们是否可以甚至可以不需要携带传感器,便可以知道我们周围的PM2.5的数值了?
为了达到目的,我们需要引出来这篇论文里的另一个insight:PM2.5在地理空间上的分布是比较平缓的。也就是说,如果我离监测站(这里监测站包括政府的监测站和AirCloud部署的廉价传感器)的距离不太远,那么我周围的PM2.5的数值应该跟监测站差不多。换句话说,那么我周围的PM2.5的数值应该跟我与监测站的距离有关系。当然了,这个insight再扩展下去,由于气象条件的影响,如果我周围的空气湿度,温度,风力大小等气象数据跟监测站附近的气象数据很接近,那么我周围的PM2.5浓度也会跟监测站的度数差不多。基于以上insight,作者开始利用GPS坐标,气象数据,以及其他影响PM2.5的信息(POI信息),来推算任意位置的PM2.5浓度。
为了推算任意位置的PM2.5浓度,我们需要描述需要推算的位置和监测站之间的关系,一个最直观的方式就是把位置的GPS坐标,气象数据,以及其他影响PM2.5的信息(POI信息等)当作特征,然后用欧式距离来计算这个位置和监测站之间的“距离”。并且根据这个距离来推算出这个位置PM2.5的真是数值。
然而,这么做不太好。因为在计算欧式距离的时候,各个特征占据的权重都是一样的。也就是说,(GPS, 温度,湿度,风力,POI)这个特征向量中,每一个特征对于距离的计算贡献一样多。这有点不公平。举个例子,比如下面这张图:
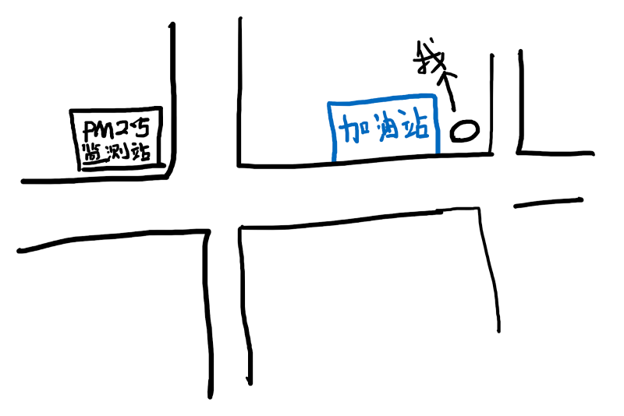
我跟监测站距离挺近的,也就二三十米。但是我的位置是一个加油站。加油站旁边汽车特别多,为其特别严重。那么我周围的PM2.5肯定就比监测站的浓度要高,甚至高出很多。这时候,我周围的情况应该跟监测站很不一样,也就是我和监测站的“欧式距离”应该很远。可是由于表示我所在位置的功能(POI)信息,在特征中,跟其他特征的权重是一样的, 这么计算下来,我和监测站的距离并不是很“远”。因此这么做是不合适的。为了描绘任意位置和监测站之间的关系(距离),作者在论文6.3章中,利用下面这个公式来描述位置和位置之间的距离:
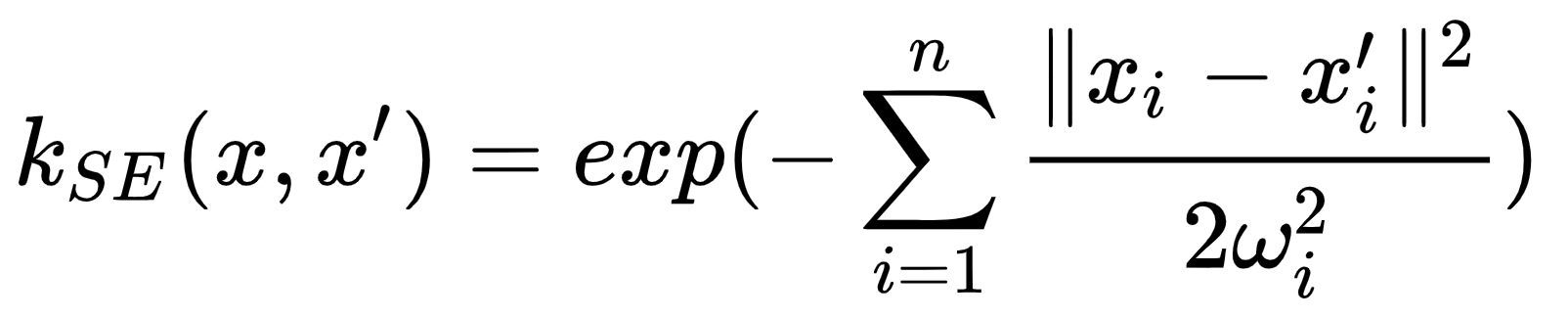
其中 x 和 x’代表着两个位置的特征。xi 表示第i个特征。 wi 表示这个特征的权重。作者之所以选用这个函数来描述两个位置之间的距离,而不是用简单的欧式距离,就是因为作者考虑这些特征之间的关系不是简单的在二维空间里的关系,而应该是更加复杂的,高维度(甚至无穷维)上的关系。而核函数正是描述高纬度上两个点之间的距离的一个工具。因此作者选用了核函数,也就是上面那个公式。 根据这个“距离”公式,我们可以计算任意位置跟我们所在城市的所有PM2.5监测站的“距离”。有了这些关系以后,作者采用了高斯回归模型,利用一个城市里面所有的PM2.5监测站的数据来推算任意位置的PM2.5的浓度。这样一来,用户无需携带任何设备也可以精准地知道自己周围的PM2.5浓度了!
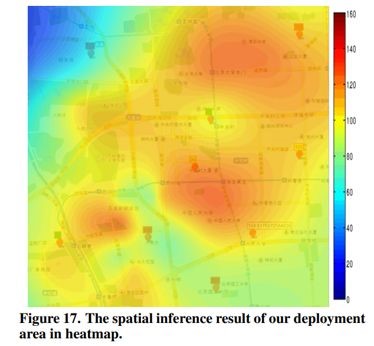
在这篇论文的实验里面,作者展示了他们预测的PM2.5在地理空间上的分布情况。这个结果很有意思。当然了,这篇论文的内容远不止如此。一个廉价的传感器是不可以直接携带的,因此作者给传感器设计了一个外壳(第4章)。传感器采集的原始数据也需要一些预处理(第6.1章)。最终,AirCloud还提供了一些API给大家,用来获取所推算的任意位置的PM2.5的结果。在这些API的基础上,还展示了几款手机APP。
下面我讲一下,如果采用挑别人论文毛病的错误思路,这篇论文的作者会面临什么样的问题?如果不明白什么是挑别人论文毛病,请看:
AirCloud这篇论文其实提到过另一篇文章”U-air: When urban air quality inference meets big data“。U-air用的是历史的PM2.5数据来推测未来的PM2.5数据。显然这种做法存在弊端,就是PM2.5有可能随着时间变化非常剧烈。比如说现在我周围PM2.5是300。30分钟以后,下了一场大雨。于是PM2.5瞬间降到了20。可是按照历史数据,我现在是300,未来一小时可能也得再300左右,不会变化太大。
这个时候,如果AirCloud的作者从挑这个毛病入手的话,恐怕就会一直解决怎么能够预测出来未来有没有雨水。这个相当于做天气预报,其难度可想而知。即使从这个角度切入以后,能作出一些新的贡献,这些贡献也是要排在U-air以后的。其贡献和影响力也要远小于SenSys的影响力。
幸运的是,AirCloud的作者并没有从挑U-air毛病的角度切入这个研究。而是从根本上思考了到底怎么知道任意位置的PM2.5的浓度。从而发现我们可以部署大量的廉价传感器来实现在地理空间上监测PM2.5。为了达到这个目的,找到了很多insights,从而设计出了一套非常漂亮的系统:
这篇论文的idea 和其中的一些insights我也介绍完了。我顺便提一下这篇论文给我的一个insight就是,我们可以利用地理空间上的分布,来推算任意位置PM2.5的浓度。然后我查了一下谷歌学术,在2021年有一篇论文引用了AirCloud,发表在了一个叫Sustainability的期刊上。这篇论文就是利用了这个insight,并加以扩展。这篇论文做的是化工厂偷排废气的监测。因为化工厂排放的废气和PM2.5有一定的关系,工厂周围的PM2.5可以利用AirCloud里面的方法来计算出来。因此,利用一个城市的PM2.5监测站,就可以实现监控工厂是否有偷排。这个idea其实只是在AirCloud的基础上稍微往前走了一步而已,并不是很复杂。然而就这么一个idea,就发表在了一个SCI期刊上。我们先不论这个期刊的级别高低,起码这一个小的idea可以让一个学生走完从提出idea到发表论文的全过程。
在这里,我再次奉劝那些还在试图从别人论文的毛病里面找idea的同学们,多去理解理解别人论文的核心的insight,多看看别人的优点。
—————————————————-END———————————————————–
我们建立了一个微信公众号:“分享科研经验的科学家”。我们会同步分享科研经验到这个公众号。在微信里,我们的文章可以更加自由地排版。文章也会更加适合阅读和传播。我们相信,经过大家的不懈努力,一定会帮助到越来越多的同学们。请大家关注我们的公众号,并且把这个传播给因为科研而痛苦的同学们。除了扫描二维码,大家还可以通过在微信上搜索“分享科研经验的科学家”来添加我们的公众号 :
